 2024年8月
2024年8月数据是推动数字化转型的核心要素,医疗大数据近几年也成为医院信息化建设中的“热词”。临床数据中心、科研数据中心、运营数据中心、大数据中心、数据中台等名词林林总总,频出不穷。医院如何在从市场上眼花缭乱的数据产品中,选择适合自身需求及发展的数据建设解决方案呢?本文从存储技术角度,看医疗大数据进化之路。
医疗大数据不仅表现为规模庞大,而且持续呈现爆发式增长趋势。随着医院物联网、互联网、人工智能等技术应用的普及,数据量势必会在增长模式上实现新跃进。此外,医疗大数据类型繁多,从病历中的诊断信息、治疗中的患者记录,到围绕整个诊疗过程的数据,应有尽有。这些数据对医院有着重要且深远的影响。因此,尽快掌握数据并发掘其潜在价值,是医院赢得可持续发展优势的战略级规划。
大数据的规模、类型和效率要求等显然已经成为传统磁盘关系型数据库难以应对的挑战。首先,传统数据库在执行数据插入和更新等操作的速率方面存在缺陷,无法满足大数据的更新速度或者用户分析大数据的速度。其次,传统关系数据库还要求预先创建数据库模式,来定义数据类型。面对种类繁多的数据信息,上述问题进一步加大了挑战的难度。随着技术的不断发展,HANA 和 Hadoop 等数据库技术应运而生。
首先是使用非关系型数据存储的技术出现,如 Hadoop。通过利用商用服务器集群,Hadoop 能够在合理的时间内处理各种快速生成的 PB 级甚至 EB6 级数据。大部分商用服务器都是一个“数据节点(DataNode)”。每个数据节点均只包含一部分数据。具体而言,Hadoop 能够将一个处理作业分解成成百上千个小作业,然后由每台服务器并行执行这些小作业,共同完成数据处理的流程。这样,只需添加更多数据节点服务器,Hadoop 即可处理 PB 级甚至更大规模的数据。此外,Hadoop 还能自动复制数据节点之间的数据,换言之,如果某个数据节点出现故障,同时执行的 Hadoop 作业以及丢失的数据都可以进行恢复。
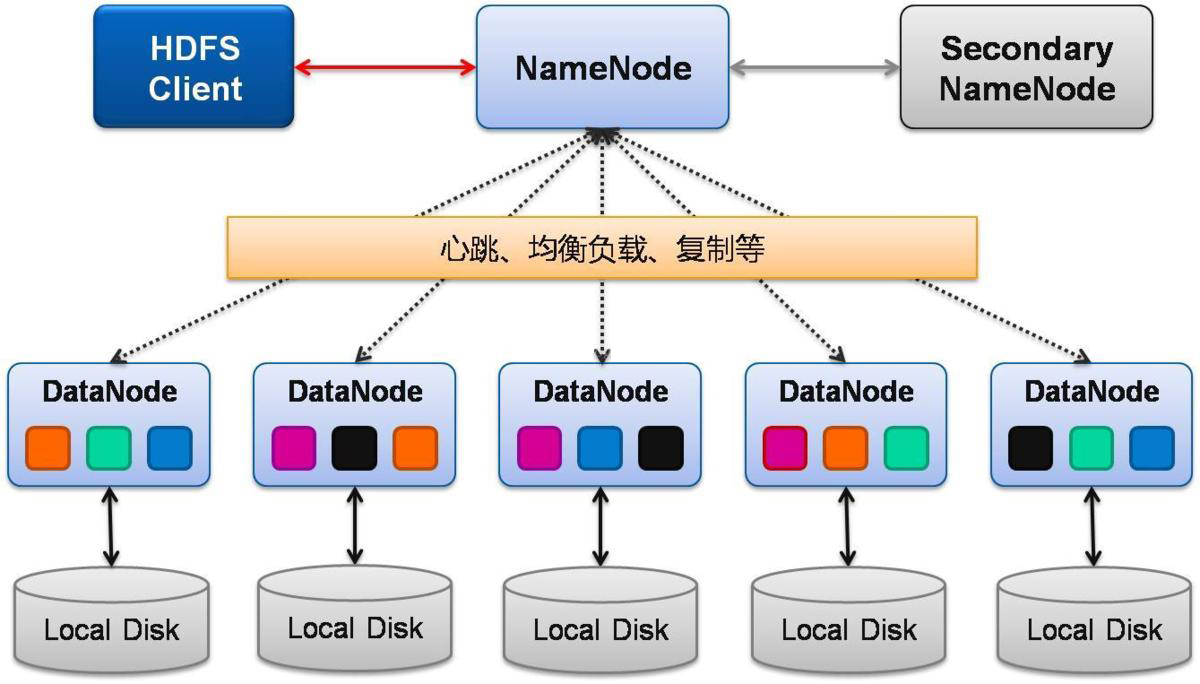
随着 Hadoop 在医疗数据领域的使用,其缺点也逐渐暴露。比如计算效率低的问题,如果 Hadoop 集群遇到了存储或网络瓶颈,数据的读写速度会变慢,进而导致计算效率低下。还有出现数据丢失的问题,Hadoop 采用集群存储,可能会导致数据丢失。并且集群扩展性差,如果 Hadoop 集群的 CPU 处理能力不足,可能无法支持新的任务或数据量的增长,这就限制了集群的扩展性。
后面随着HANA内存数据库和HANA 软件等数据库应用工具先后面世,医疗大数据的解决方案有了更多可选项。此类应用工具具有超过 20x 的压缩率,可将 100 TB 的医疗数据集压缩至 3.78 TB,并能秒级完成整个数据集的分析查询。为了保证高性能,几乎所有数据都由处理引擎保存在主内存中,但是数据也必须持久化至数据持久层,以便在系统显示关闭或出现故障后重启时进行备份恢复。
众所周知,列式存储非常适合用于处理对大量数据进行的分析型查询,同时采用数据压缩使得单个节点可以保存更多的数据,还利用诸如 RLE 进行聚合计算等方式来提升查询处理速度。
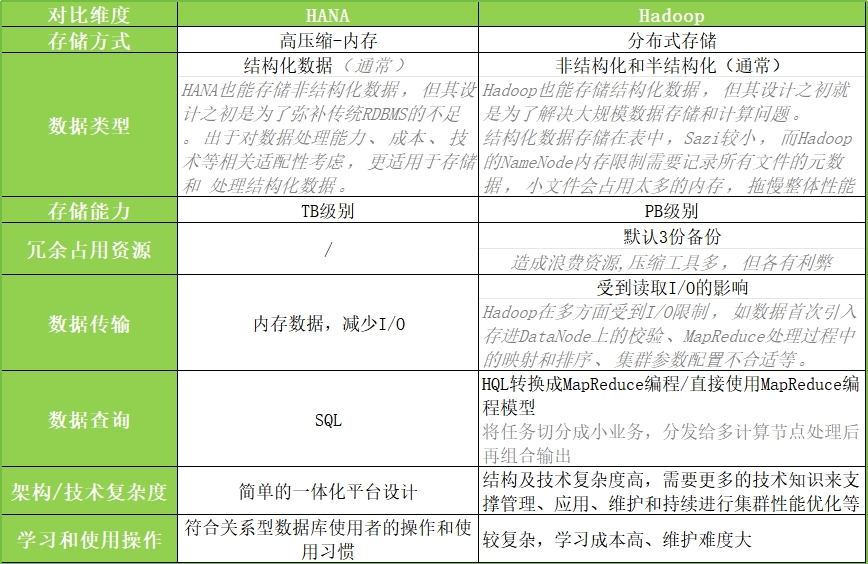
通过对比可知,Hadoop集群式存储更适用于对大规模数据集的管理,而且开源的Hadoop,虽然前期简单建设投入成本低,但是要优化其数据处理效率、提升安全性等,需要基于其现有的生态周边进行复杂架构的搭建,相对而言最大的弊端在于延迟性高、搭建复杂,维护和使用门槛更高。
HANA数据库技术则更加轻便灵活,其软硬件一体的平台化设计,不仅能够帮助医院实现全院级数据一库存、管、用,并且HANA所具备的“全、快、易”特点,能够确保其在面向数据存储和处理的时候做出极为敏捷和高效的响应。并且HANA更加适用于对数据查询和分析效率有较高要求的医院数据使用场景。在面对医疗大数据的应用方面,一库同构是未来发展方向,医院需要从传统的数据库技术路线中跨越出来,而 HANA 数据库技术无疑是当下最适用的选择之一。
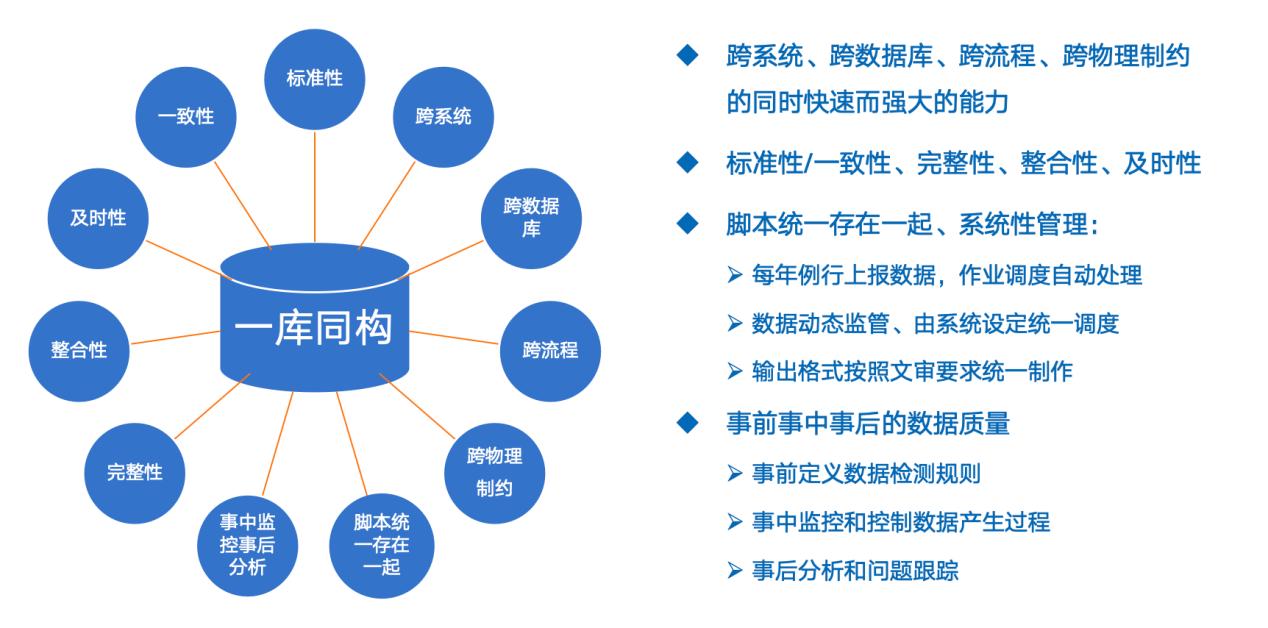
医院的发展涉及到对医院全方位多维度的考量和规划。而数据作为推进新时期现代化医院实现高质量、精细化、智慧化发展的新要素,数据的建设发展要自上而下,考虑顶层设计一体化建设;同时也要自下而上,打好“数据地基”以确保构建好用、实用的“数据高楼”。
天助基于HANA为医院量身打造的“全院一库”大数据平台,是支撑医院推进数据发展的新基建,通过实践表明,在HANA“全、快、易”的能力支撑下,天助“全院一库”大数据平台在解决医院对多类型、大规模数据进行的复杂查询和高效响应要求的实质性挑战方面表现优异。同时,针对医院数据的可持续发展需求,天助还提供了“数据动态分层”管理预案。
平台在扮演数据的“供应”角色时,可通过“租户”视图来提供敏捷的供应能力。除此此之外,天助还在持续围绕“全院一库”打造和壮大“1+N”数据加应用的创新的生态,旨在帮助医院夯实数据基础、盘活数据存量、融合好数据增量,持续推动数据价值释放,产生数据效益。