 2024年4月
2024年4月在当今这个数据驱动的时代,医院对于数据处理的需求日益增长。传统的关系型数据库(RDBMS)和非关系型数据库(NoSQL)虽曾是数据处理的主力军,但随着技术的发展,它们开始显露出局限性。
首先,关系型数据库以表格形式存储数据,非常适合处理结构化数据和复杂的查询操作。然而,随着数据量的激增,他们对于大规模数据的处理往往显得力不从心。从数据库技术本身来说,因为受限于磁盘I/O的瓶颈,其响应速度大受影响;其次,为了保持数据的一致性,传统关系型数据库通常需要牺牲速度来执行事务和复杂查询。另外,传统关系型数据库很难实现架构的横向扩展,从而导致存储容量资源方面也存在瓶颈,这也是关系型数据库难以应对大规模数据存储和管理的重要原因之一。
非关系型数据库,或称为NoSQL数据库,为应对大量非结构化或半结构化数据而生。非关系数据库提供了灵活的数据模型,面向大规模数据表现出稍快于关系型数据库的读写能力。但是,NoSQL数据库在处理复杂的数据分析和事务时,往往缺乏足够的支持,这对于普遍具有对数据进行深入分析需求的医院来说,无疑是一个明显的短板。其不支持事务的AICD特性,从而数据的质量较差,导致数据后期的应用效果误差也较大。从数据的取用方面来说,由于NoSQL也是采用磁盘存储数据,数据读取同关系型数据库一样会受制于磁盘的I/O,严重降低数据处理操作的速度。
在这样的背景下,HANA内存数据库应运而生,它不仅突破了传统数据库的限制,还以其独特的优势重新定义了数据管理的标准。那么,HANA又是如何突破这些限制的呢?
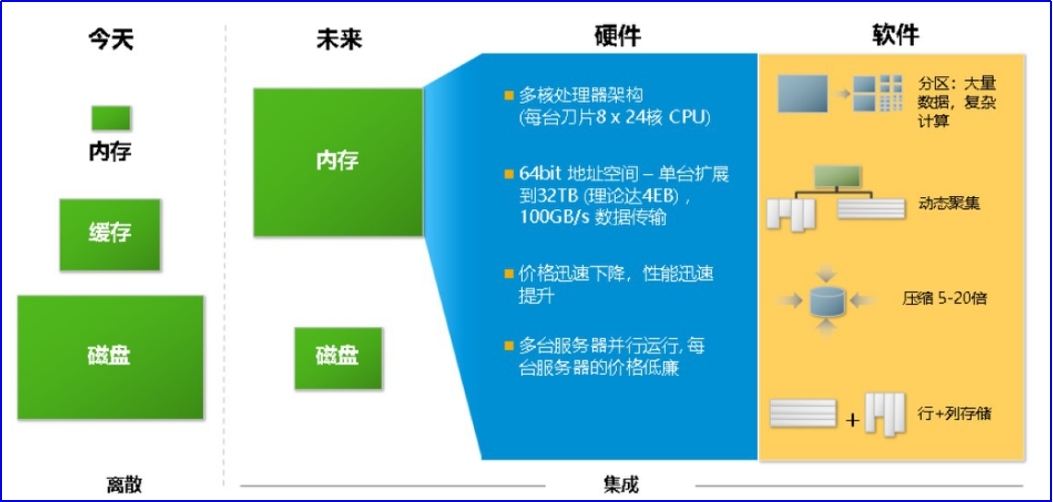
首先,HANA是一个高性能的软硬件一体的内存数据库。它将数据存储在内存中,而不是磁盘上,这意味着数据的读取和写入几乎不受物理存储限制。而在数据的处理方面,HANA采用多核并发的数据处理机制,并将应用逻辑和数据计算由应用层转到数据层进行。HANA从存储数据到数据读取供用方面运用了多重提速机制,极大程度提升数据处理的速度,可达“亿表一秒”全库查询反馈。
其次,HANA默认对数据采用列式存储(也支持选择行式存储),并进行高倍压缩(压缩比高达10-20倍)。HANA还进一步采用数据动态分层存储,按数据的活跃程度将数据分为“热、温、冷”数据进行存储管理,活跃的热数据存储在内存,冷数据则对接数据湖(如Hadoop)进行数据的无缝接管,而温数据则动态游离在冷数据及温数据之间,不占内存,又能随时被调用。在对接应用时,HANA将传统业务层面处理的数据计算转移到数据层处理,免去数据出库-处理-返回数据库存储的路径,也不占用应用的性能。这样的整体数据存储方案,同时保障了其性能和数据内存容量,支持将全量级的大规模数据全部汇聚到同一个数据库进行统一存储、统一管理、统一供用。

另外,HANA还提供了无与伦比的灵活性。无论是结构化数据还是非结构化数据,HANA都能够轻松处理。它支持“多租户”以视图形式从HANA数据库当中获取数据并加以应用,还支持多种编程语言和API,使得开发者可以轻松集成多种应用程序和服务。
最后,但同样重要的是HANA的安全性。它提供了多层次的安全措施,包括加密、访问控制和审计日志等,确保数据的安全性和合规性。
总体来说,HANA内存数据库是继传统关系型和非关系型数据库后的又一数据库技术高地,其优势主要体现在面向大规模数据存储及处理时的“全、快、易”能力。
在数据发展的历程中来看,随着数据爆发式的增长,非关系型数据库应运而生,主要意图解决关系型数据库在处理大规模数据方面的制约,但其却丢失掉了关系型数据库的一些优势能力。人们试图结合各种数据库部署架构来实现优势互补,但同时也不免不了劣势继承,无法很好的平衡各方制约。相对而言,HANA内存数据库从存储能力、数据处理效率、数据及架构的灵活易用性等方面都超越了传统的关系型和非关系型数据库。它的出现解决了传统数据库面临的挑战,是支撑企业及机构实现数字化转型,打造数据底座新基建更佳数据库技术选型。